Exploring the data using gaussian mixture models
We use gaussian mixture models (GMMs) to improve our understanding of the attack class data.
Creating a new dataset
From (1), we know that 9 of the 12 attack classes have a small number of data representatives (between 11 and 10293). We create a reduced dataset that only contains the data corresponding to the 9 low-volume classes. Note that the BENIGN, DoS Hulk, PortScan, and DDOS data is not in the reduced dataset (2).
Setting up a GMM experiment
GMM is an unsupervised learning technique to cluster the provided input into a predetermined number of classes. We use the reduced dataset (minus the labels) as the input to GMM.
For each run of the experiments, we iterate through different “number of components” as input to the GMM module. After each GMM iteration, we extract the Bayesian Information Criteria (BIC) - a measure of the goodness of fit of the model iteration to the data.
GMM is sensitive to initialization and can only find the local optima for the parameters that it estimates. Thus we carry out multiple runs of the experiment to guard against outlier results.
Interpreting the BIC
The BIC converts the goodness of fit achieved by a model into a scalar metric compared across models. The BIC accounts for the number of parameters estimated by the model.
Usually, higher values of the BIC imply a better model. Hower for BIC values returned by Scikit-learn’s “mixture” module, lower values of BIC are deemed better.
We plot the BIC values for each GMM run. The x-axis represents the number of components that GMM is asked to fit the data into, and the y-axis represents the BIC. We see from the plot in (3) that BIC values have an “elbow” somewhere between 7 and 15 components, suggesting that the number of classes is in the range [7, 15]. The number of classes actually represented in the data is 9, within the scope of the elbow. However, there isn’t a clear and sharp leveling-off of the BIC at 9 components.
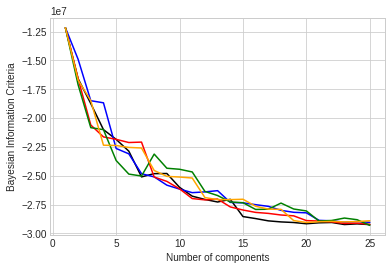
One of the attack classes (Web Attack) is made up of three sub-classes that had independent labels in the original data (Web Attack - Brute Force, Web Attack - XSS, Web Attack - Sql Injection) but were discussed as one category in (4). Even accounting for these as separate classes does not explain the lack of a sharp elbow (at 10).
We conclude that either GMM does not represent the data well, or the number of clusters in the data is greater than the number of attack classes.