A composite of char and token-based models
We continue our experimentation by creating a neural network model composed from a character and a token (word) based model,
Inspiration for the model
Previously, we experimented with a character-based model that used CNN to extract features from the data (1, 2).
We also experimented with an LSTM model with a learned embedding (1) on tokens. (3) suggests an alternate way to extract features from tokens and signals from a sequence of features - via a CNN block followed by an LSTM block.
(4) documents a composite model that combines the character-based model with a token-based CNN-LSTM model.
Composite model implementation
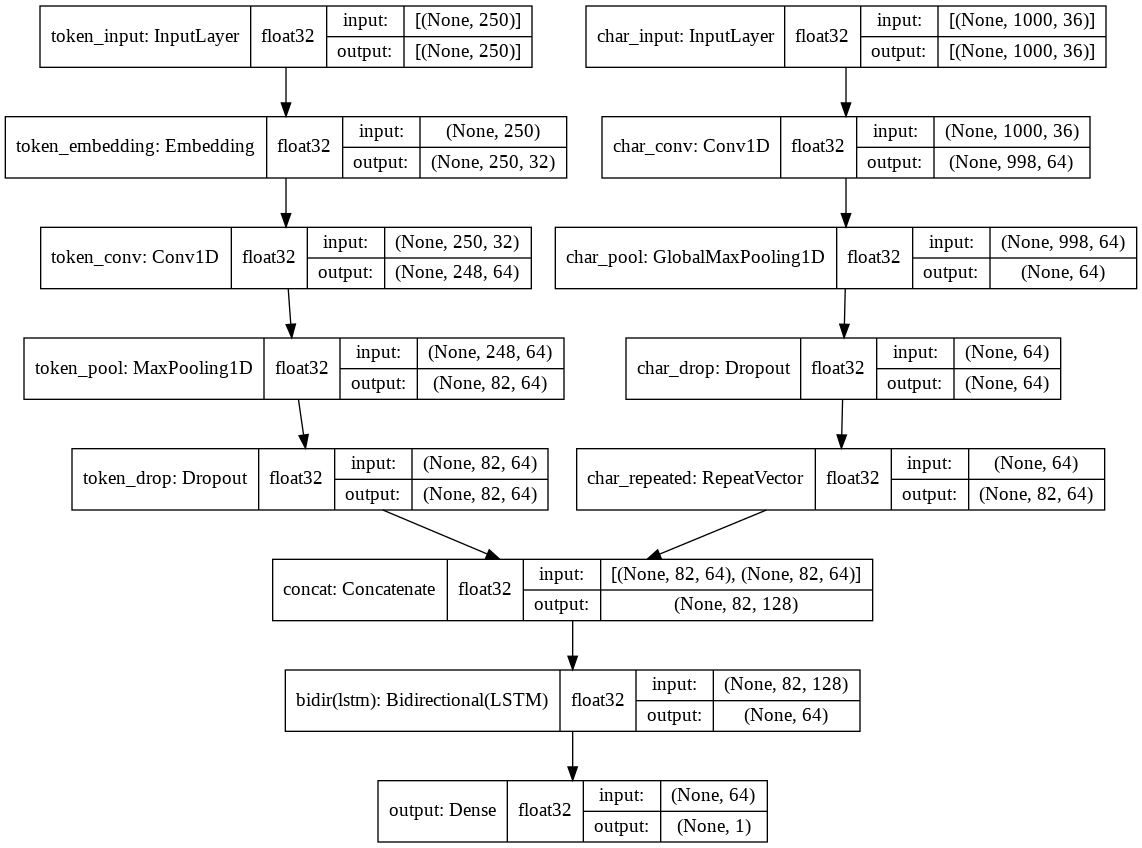
We implement the composite model (5) described in (4). The diagram below shows the network.
The token part of the model makes a few adjustments to the model in (6): in particular, we hold the maximum number of allowed tokens to 50,000 to keep memory consumption in check.
The character part of the model makes a few adjustments to the one in (1) - to simplify the implementation, we encode characters previously prepared for the token portion of the model, rather than the raw text.
Model performance
We observe an accuracy score of 98.43%, an F1 score of 83.85%, and an AUC score of 96.72%.