Word2Vec experiments to match the performance of Logistic Regression
Since Word2Vec performed better than FastText, we experiment with hyper-parameters used to generate the embeddings.
First, we expand the unlabeled data available by obtaining and process another jobs dataset from Kaggle (1).
Second, we change from the continuous bag-of-words that is the default in Word2vec to Skipgrams.
Finally, we expand the window size used by Gensim to create embedding from the default 5 to 10. The bigger window allows the Word2Vec algorithm to look at more neighboring words while generating embeddings (2).
The above changes (3) result in performance close to that of the bag-of-words + Logistic regression model.
- Accuracy: composite 98.40% vs. logistic 98.58%
- F1 score: composite 84.36% vs. logistic 86.52%
- AUC score: composite 98.62% vs. logistic 97.48%
The diagram below shows the ROC curves for the four models that we discussed recently.
- Ngram-TfIdf-Logistic is the model in (4)
- Char-CNN is the model in (5)
- BoW-Logistic is the model in (6)
- Word2Vec-Word-Char is the composite model in (3) and the one discussed above
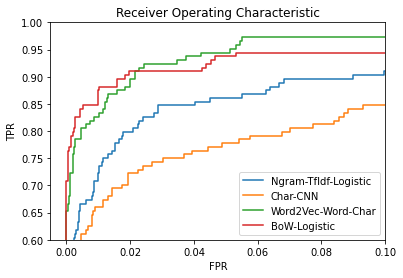
The ROC curves demonstrate that the easy-to-interpret “bag-of-words with logistic regression” model provides satisfactory results while remaining simple.